1편에 이은 2편입니다.
browser-use + playwright로 페이지 탐색, PDF다운로드까지 맡겨보기
지난번에 검토하기로 했었던 browser-use를 먼저 사용해보기로 했다. 이유는, 잘만 동작한다면 크롤러를 만들면서 많은 시행착오를 겪는 시간을 줄일 수 있기 때문이다.
예전에 Tesseract OCR을 사용해서 크롤링 프로그램을 만들어본적이 있는데, 직접 최적의 세팅을 해주는데 많은 리소스를 소모했던 경험이 있다.
Gemini의 경우 무료 API Key를 제공해주고, 테스트 환경 정도는 충분히 커버가 되기 때문에 browser-use를 사용해보기에 최적의 조건이었다.
한계
browser-use 라이브러리의 경우, Playwright로 브라우저 위에서 AI를 이용해 동작하는 것이기 때문에 PDF를 다운로드 받는 것 까지는 성공했지만, local에 받은 파일을 열어서 분석하는 행위는 불가능했다. Playwright를 사용하는 것이기 때문에 당연한 결과다.
성과와 개선방향
크롤링 부분을 크게 해결할 수 있을 것 같은 가능성을 본 것만으로도 오늘 큰 성과를 달성했다고 볼 수 있다.
아래는 프롬프트를 직접 입력해서, 테스트를 수행한 결과물이다.
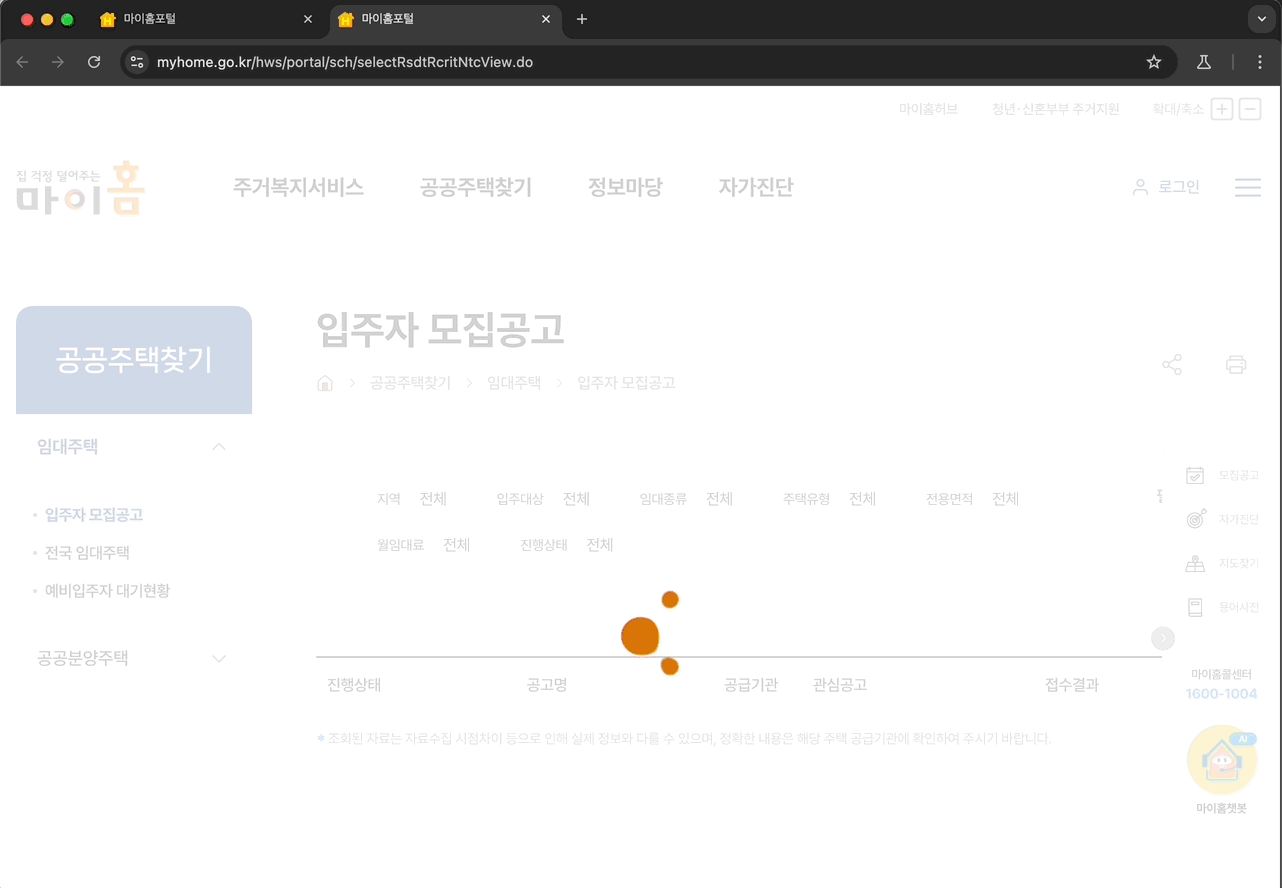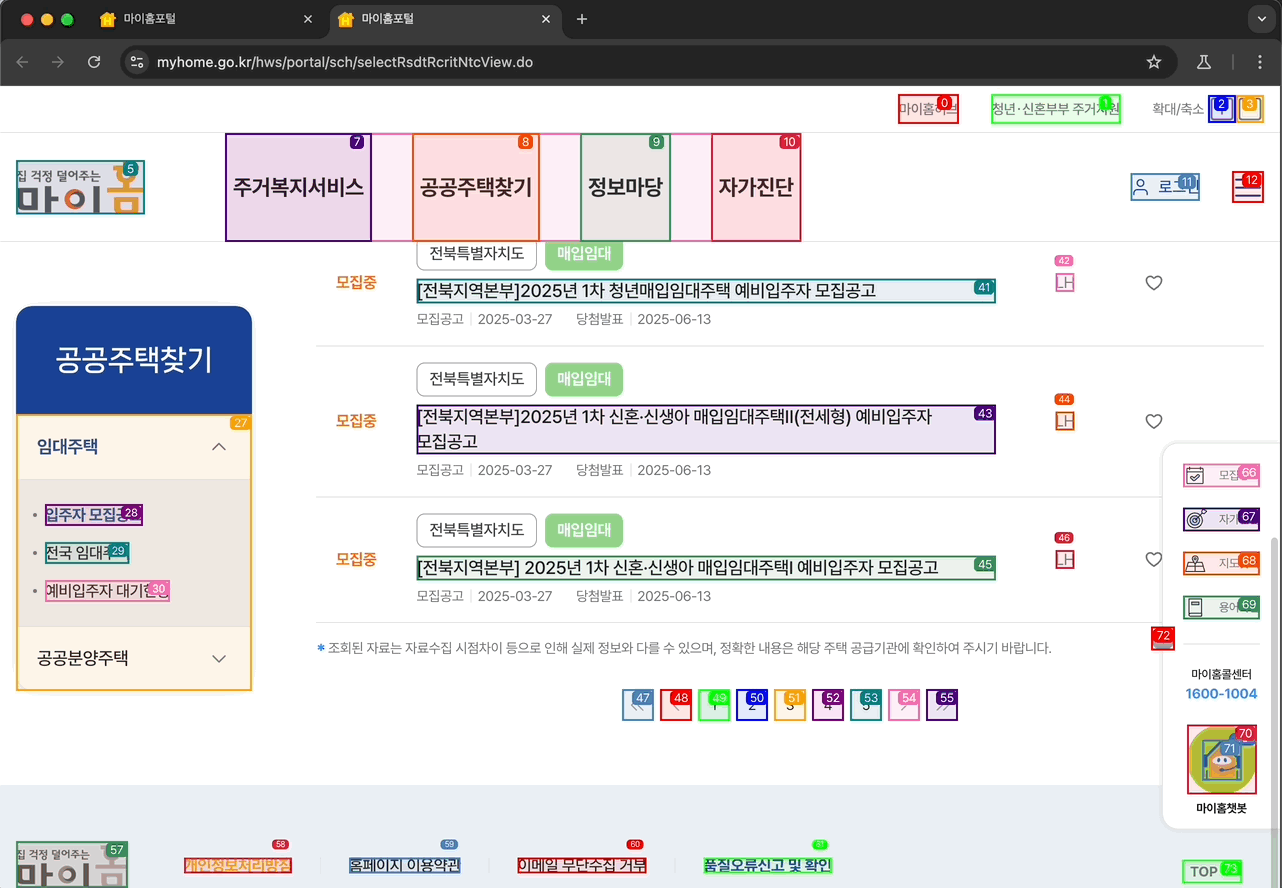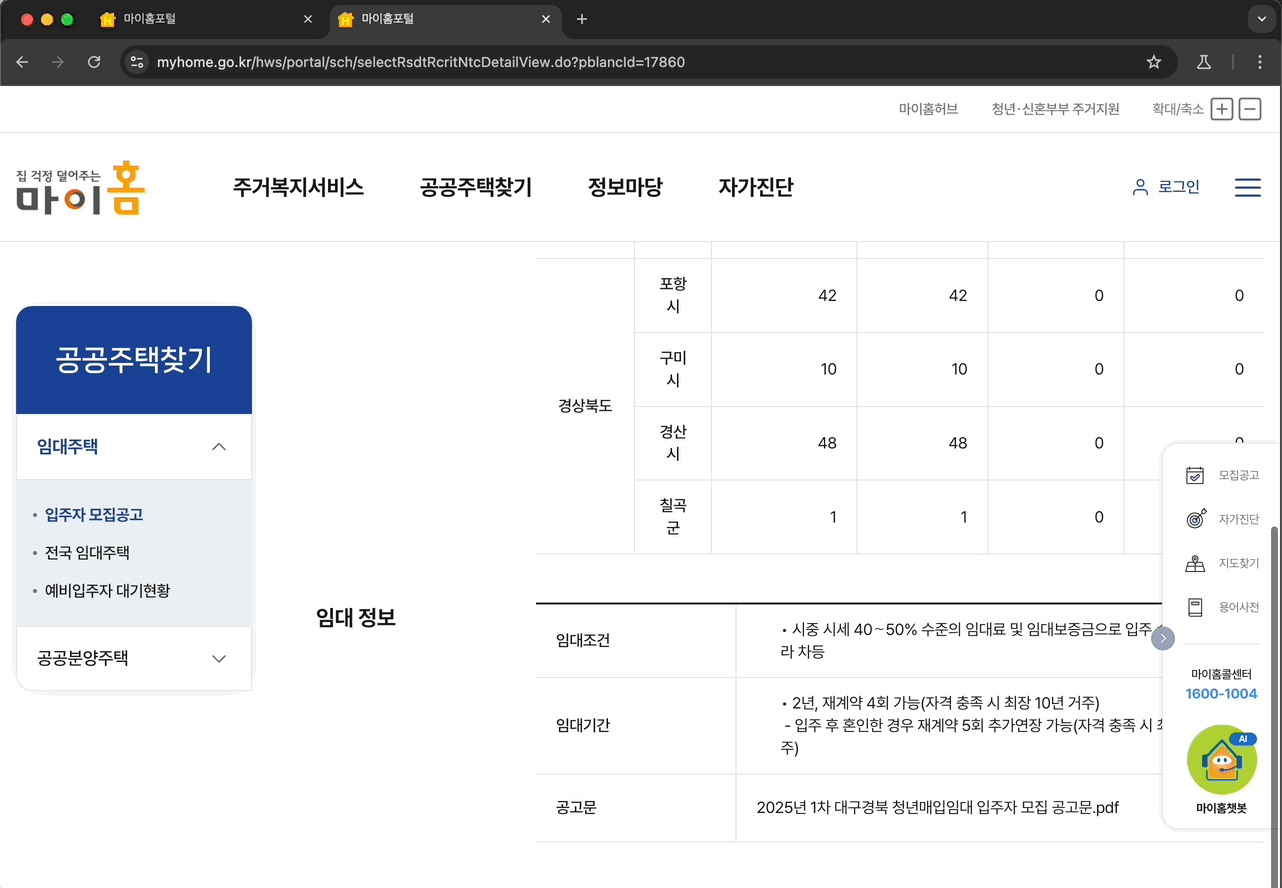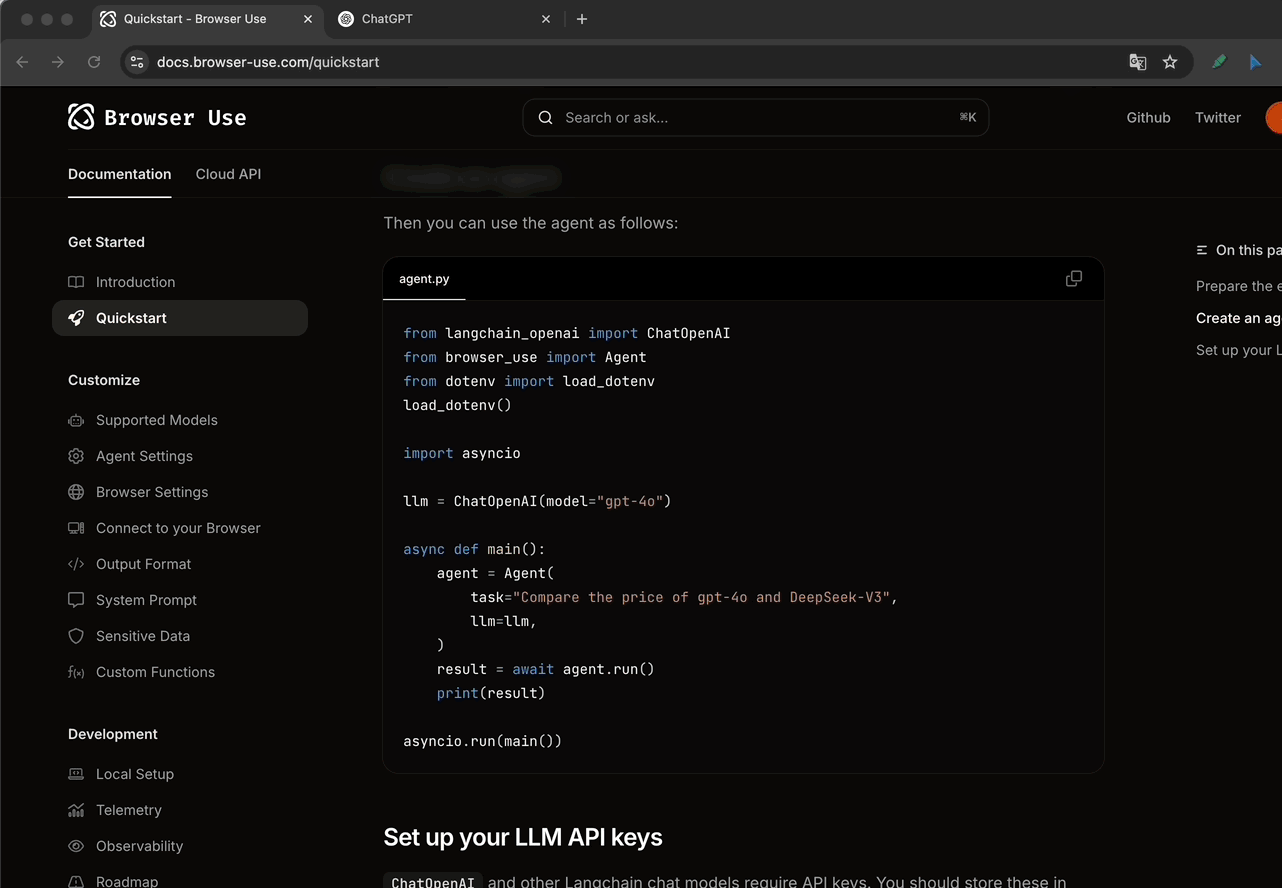
입력했던 프롬프트는 다음과 같다. “‘공공주택찾기’ 메뉴로 진입한 뒤, ‘입주자모집공고’로 들어가서, 화면 하단에 출력된 공고 리스트 중, 첫번째 공고의 공고명을 클릭한 뒤, 공고 내부에 PDF파일을 다운로드 받아줘.”
내가 의도한 서비스를 구현할 수 있을 정도의 기술력이 현재 세상에 구현되어있는지 보고 싶었는데, 큰 산을 하나 넘은 느낌이다. 좀 더 디테일하게 다뤄봐야겠지만, 생각 그 이상으로 잘 수행해주는 것 같다.
다음 문제는, 별도의 PDF 파일 분석 엔진단을 만들어야 한다.